Conception, Construction and Evaluation of a Raspberry Pi Cluster (4/4)

The goal of this work is to create an affordable, energy efficient and portable mini-supercomputer. Ideally, a cluster computer with little or no carbon footprint, individual elements that are inexpensive to replace, and a portable system that can be easily disassembled and reassembled.
Evaluation
After the cluster has been configured and Kubernetes is ready for use, the entire system is evaluated. The requirements set in advance (see Requirements) are critically reviewed, target and actual values are evaluated, and various comparisons are made. This prototype is ideally suited to illustrate and substantiate the research question addressed in this thesis. Section Use case SETI@home deals with a use case that provides information about the extent to which and the purpose for which this custom cluster construction can contribute to scientific research.
Scalability
Kubernetes enables easy scaling of applications or pods and the applications within them. Enabled autoscaling scales pods according to their required resources up to a specified limit. In the following example, we test the autoscaling of our cluster using a simple web application and verify the automatic scalability of the system: 1
For this purpose, a Docker image based on a simple web server application is used. This Docker image contains a single web page, which causes a maximum CPU load by simulated users when called. The Docker image is launched, causing a web server to run with the corresponding web page as a pod. Kubernetes' autoscaler is enabled with the following configuration: 2
-
KUBE_AUTOSCALER_MIN_NODES = 1: The minimum number of nodes to be used is one.
-
KUBE_AUTOSCALER_MAX_NODES = 4: The maximum number of nodes to be used is four. The fifth node thus retains the function as master.
-
KUBE_ENABLE_CLUSTER_AUTOSCALER = true: Activation of the autoscaler.
The pod with the web server container is started with the following properties:
-
CPU-PERCENT = 50: This configuration value specifies the value that is maintained to keep all pods at an average CPU load of 50 percent.
-
As soon as a pod requires more than half of its available computing power, another pod instance is automatically replicated or an exact copy of the running pod is created.
-
MIN = 1: At least one Pod is used for scaling.
-
MAX = 10: A maximum of ten replicas of a pod can be used for scaling.
After the pod is started and user load is simulated, an increase in CPU load to 250 percent is observed and that seven pods have already been swapped out or scaled:
|
|
Listing 5: Observing CPU utilization increase to 250% while pods are swapped out to provide resources.
Two minutes after the user load simulation stops, the CPU utilization drops back to zero and the drop from seven to one pod can be seen.
|
|
Listing 6: Watching CPU utilization drop to zero percent and drop to one pod.
As can be seen (see Listing 1), it is very easy to dynamically adjust the number of pods to the load, by enabling the cluster autoscaler.
Automatic and dynamic scaling can also be very helpful when there are irregularities in cluster utilization. For example, development-related clusters or continuous computing operations can be run on weekends or at night. Compute-intensive applications can be better scheduled so that a cluster is optimally utilized. In all cases, the cluster can be used optimally. Either reduce the number of unused nodes to save energy or scale to the limit to provide enough computing power. Depending on which case occurs, a dynamically scaling cluster ensures that at high or low utilization, all tasks are solved in the most efficient way.
Fail-safe
As with each element of our cluster, we ensure that more than one instance of each component is running simultaneously. Setting the number to five physical nodes per enclosure is one reason for creating the possibility of optimal scaling and appropriate resilience. The greater the number of nodes, the less likely there is to be a total failure or bottleneck in scaling capabilities. Load balancing and availability are closely related to cluster resilience. One way to ensure that a master node is highly available is to allow a worker node to step in as master. Kubernetes already inherently brings the function that as soon as a master node fails, a worker takes its place. The active/passive design is already in use. Second, this failover implementation is active for all worker nodes. Figure 28 shows how load balancing and failover work together to keep this cluster alive in the event of a master as well as worker node failure. The actors here are the cluster components etcd, kube-apiserver, kube-controller and kube-scheduler (see Google Kubernetes). The Kubernetes API server, controller, and scheduler all run inside Kubernetes as pods. This means that in the event of a failure, each of these pods will be moved to a different node, thus preserving the core services of the cluster. Here, one considers potential failure scenarios:
-
Loss of the master node: If not configured for HA, loss of the master node or its services will have a severe impact on the application. The cluster will not be able to respond to commands or deploy nodes. Each service in the master node is critical and is configured appropriately for HA, so a worker node automatically steps in as the master.
-
Loss of worker nodes: Kubernetes is able to automatically detect and repair pods. Depending on how the services are balanced, there may be an impact on the end users of the application. If any pods on a node are not responding, kubelet detects this and informs the master to use a different pod.
-
Network failure: The master and worker nodes in a Kubernetes cluster can become unreachable due to network failures. In some cases, they are treated as node failures. In this case, other nodes are used accordingly to replace the respective node that is unreachable.
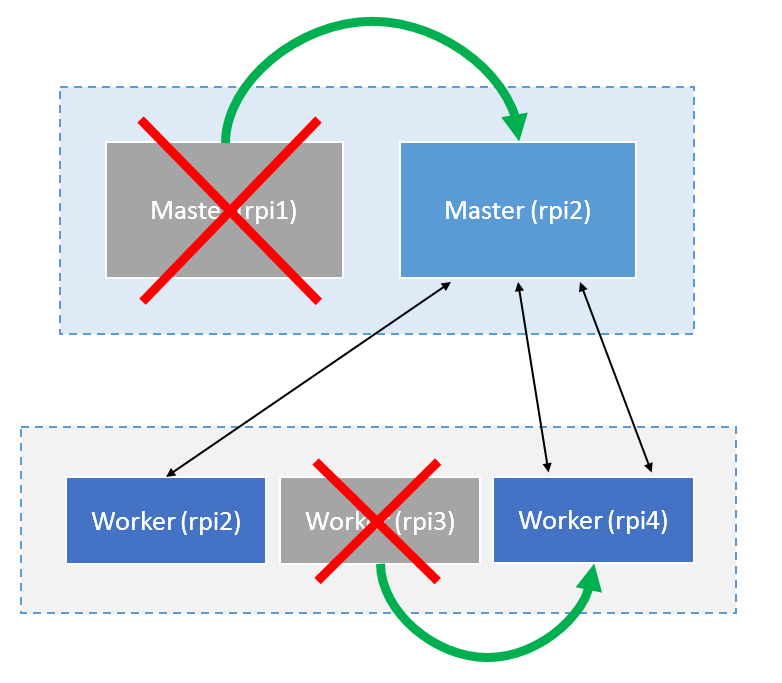
Figure 30: Failure and takeoverscenario of the master node rpi1 and the worker node rpi3.
Kubernetes is configured to be highly available to tolerate the failure of one or more master nodes and up to four worker nodes. This is critical for running development or production environments in Kubernetes. An odd number of nodes is chosen so that it is possible to keep the cluster alive even with only one node. A cluster node can continue to operate in the last instance once a node is only acting as a master and worker. In this state, the cluster is neither highly available, fail-safe, nor completely resilient, but it survives.
Cost efficiency and performance
Looking at the costs, there are two sides to the story. With the total acquisition costs, minus the contributed effort to assemble, install and configure the cluster, the value of the investment is exactly 358.79 EUR. This construct is contrasted with a simple Linux cluster for comparison. This Linux cluster consists of commercially available PCs with comparable core data to that of the Raspberry Pi nodes.
| Raspberry Pi 3 Model B | Linux PC | |
|---|---|---|
| CPU | Cortex-A53 1.2 GHz Quadcore | Intel Celeron J1900 2 GHz Quadcore |
| RAM | 1024 MB | 4 GB RAM |
| Network | 100 Mbps | 1000 Mbps |
| Current Consumption | max. 4 Watt / h | max. 10 Watt / h |
| Price per computer | approx. 35 € | approx. 95 € |
| Total price | approx. 175 € | approx. 475 € |
Table 2: Cost comparison of the core components of Raspberry Pi and Linux PC.
If we now compare the core data, we can see that the comparison system is definitely associated with higher acquisition costs. It is important to mention that this comparison primarily focuses on the costs and not the performance of the individual systems. It is obvious that a Linux PC, based on a CISC processor architecture, definitely achieves higher FLOPS than an ordinary ARM processor. Nevertheless, it becomes clear in the first approach that, despite the lower performance, there is a significant difference in terms of cost. Especially when performance per watt is calculated. Due to the compact design of the Raspberry Pi and the accommodation of all components, such as the integrated power supply and GPU, it is a competitive partner for the Linux PC.
In relation to the costs, the question arises how the comparison systems perform in terms of performance. For this, a performance test is performed with the help of sysbench. Sysbench is a benchmark application that quickly gives an impression of the system performance. For this purpose, a CPU benchmark is run on both systems, which calculates all prime numbers up to 20000, and the results are shown in Table 3 and Figure 31.
| Raspberry Pi 3 Model B | Linux PC | |
|---|---|---|
| CPU benchmark | Prime number calulation | Prime number calculation |
| Threads (process parts) | 4 | 4 |
| Limit | 20000 | 20000 |
| Calculation time | 115.1536 seconds | 11.2800 seconds |
Table 3: Comparison times of the prime number calculation up to 20000.
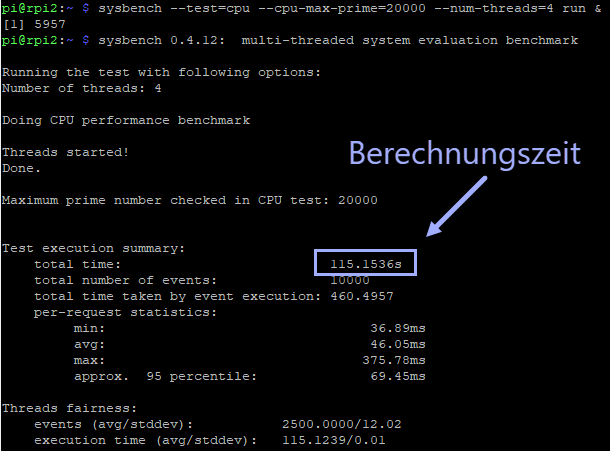
Figure 31: Results of the sysbench benchmark run on node rpi2.
The difference in the calculation time is clearly visible. There is a difference of 104 seconds. According to the visible comparisons and as already mentioned in the cost comparison, there is no question that a Linux PC based on the CISC architecture has a higher CPU performance than the Raspberry Pi with an ARM architecture.
Energy efficiency and cooling
ARM processors, such as those installed on the Raspberry Pi, have a high energy efficiency with a clock frequency of 1.2 GHz and a power consumption of max. 4 watts. The average power consumption is about 2 watts in idle mode. The switch consumes 2.4 watts at 0.2 amps of current and 12 volts. The total wattage output of the USB charger is made up of all components and sits at the end of the power chain. Summarizing with all installed components, you get a total power consumption of 13.75 watts in idle and 34 watts at maximum load (see Table 4).
| Power consumption | ||
|---|---|---|
| Component | Idle | maximum |
| Raspberry Pi 3 Model B | 2 Watt | 4 Watt |
| Edimax ES-5800G V2 Gigabit Switch (8-Port) | 2.4 watt | 2.4 watt |
| LCD display module 1602 HD44780 with TWI controller | 0.1 watt | 0.1 watt |
| Antec TRICOOL 92mm 4-pin case fan | 1.25 watt | 1.25 watt |
| Anear 60 Watt USB Charger (6-Port) | - | - |
| Total power consumption | 13,75 Watt | 23,75 Watt |
Table 4: Total power consumption of the PiCube in idle mode and maximum CPU load of 100%.
In the following test, CPU load is generated using the Sysbench prime calculation program and advantages and disadvantages are shown by using active cooling and passive cooling elements. We read system values such as temperature, clock frequency and voltage using the following commands in each case: 3
|
|
Listing 7: Commands for querying temperature, clock frequency and voltage.
In the following, we look at three temperature curves in the case. The CPU clock frequency is 1.2 GHz and the CPU voltage is 1.325 volts over a period of 5 minutes:
- Temp1: In case, without heatsink on SoC, without active cooling.
- Temp2: In case, with heatsink on SoC, without active cooling.
- Temp3: In case, with heatsink on SoC, with active cooling.
| **CPU utilization (%) | Temp1 (°C) | Temp2 (°C) | Temp3 (°C) |
|---|---|---|---|
| 0 | 39 | 39 | 44 |
| 100 | 77 | 77 | 82 |
Table 5: Measured values of heat generation without active cooling.
Next, we look at three temperature profiles of a Raspberry Pi processor. The CPU clock frequency is 1.2 GHz and the CPU voltage is 1.325 volts over a period of 10 minutes:
- Temp1: CPU, without heat sink on SoC, without active cooling.
- Temp2: CPU, with heat sink on SoC, without active cooling.
- Temp3: CPU, with heat sink on SoC, with active cooling.



| **CPU utilization (%) | Temp1 (°C) | Temp2 (°C) | Temp3 (°C) |
|---|---|---|---|
| 0 | 44 | 32,2 | 27,8 |
| 100 | 83,3 | 83,3 | 69,8 |
Table 6: Measured values
The heat development of the circuit boards of each individual computer is also taken into account. Although this is low, it increases constantly with the number of nodes installed in the case. The heat development is about 35 degrees Celsius with an average load of a single board. With 5 nodes, this is already around 38 degrees, which corresponds to a factor of around 1.08 per node. If all 5 nodes are overclocked by increasing the processor's clock frequency, this factor increases to 1.1. Temperature differences of 10 degrees in the case and the processor prove that the maximum performance of all hardware nodes cannot be exploited without appropriate cooling. Passive heat sinks and an already implemented active cooling with the help of a case fan can help here. There is no question that the optimized airflow inside the case also contributes to the improved cooling performance.
Use Case SETI@home
After evaluating the cluster, we turn to a use case from the scientific domain. A current PRC project of BOINC is SETI@home, a scientific experiment run by the University of California at Berkeley that uses computers connected to the Internet in the search for extraterrestrial intelligence. One participates by running a free client program on a computer that downloads and analyzes radio telescope data. This project relies on the concept of grid computing. Data sets to be processed are divided into smaller data sets and distributed to all participating clients, who compute and communicate the results to the distributor, which reassembles the computations into an overall data set. The current computing power of the entire BOINC grid is 20600 PetaFLOPS, distributed over nearly 0.9 million computers. SETI@home has a share of about 19.1% of this. 4
In the following, container virtualization is exploited and pre-built BOINC client images of Docker are used. These images are prefabricated containers, which are started as scalable pods on the PiCube and scale automatically in order to utilize the entire computing power of the cluster. To do this, you register with the SETI@home project and create an account. Using this account data, you generate a container application called k8s-boinc-demo and start it on the cluster with a scaling limit of 10 pod instances. In Figure 32, you can see from the Kubernetes dashboard how the pods are distributed evenly or according to workload across worker nodes rpi2 to rpi5 after launch. 5
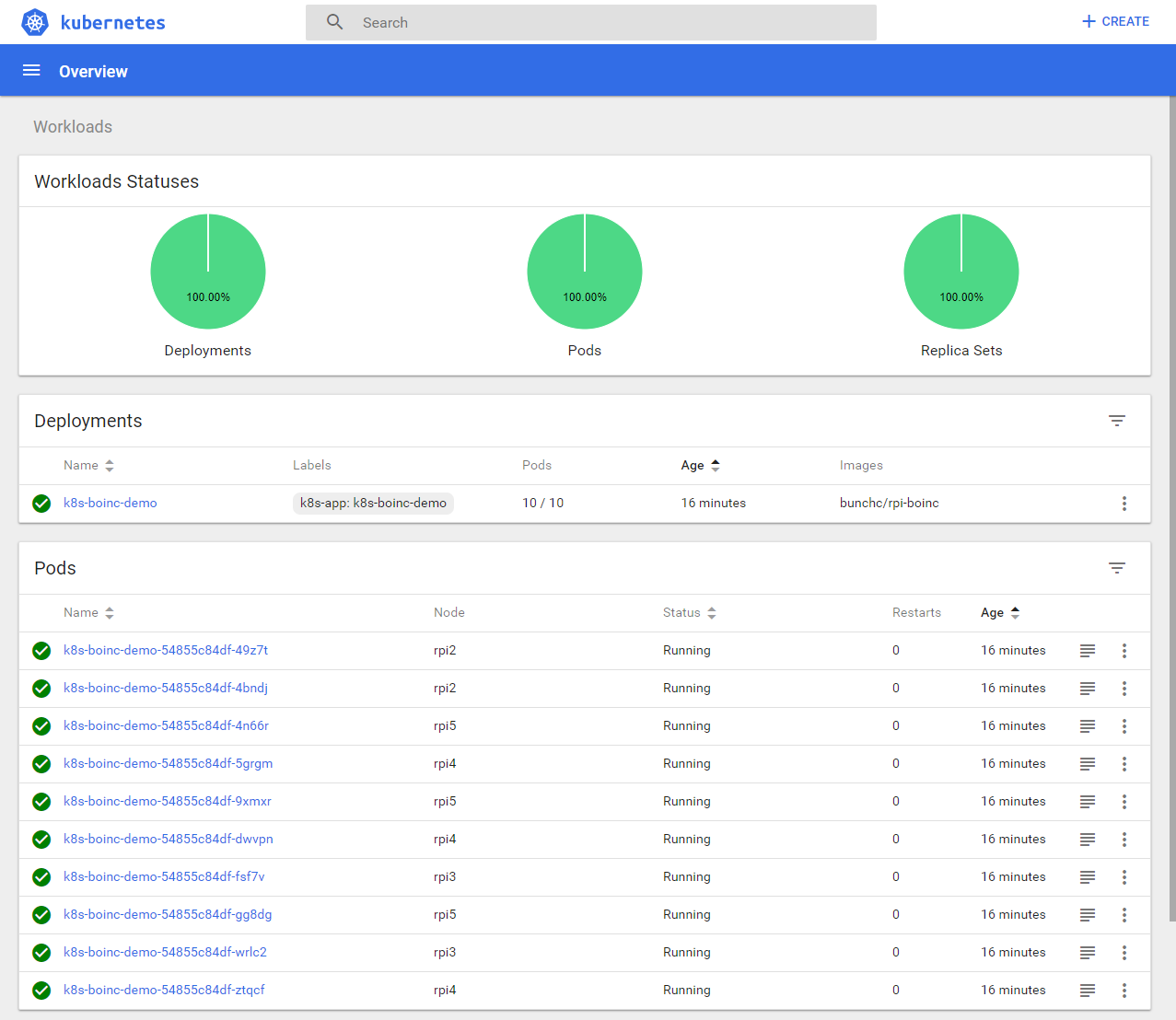
Figure 32: Overview of the utilization, status and distribution of the pods on the nodes rpi2 to rpi5.
Within the SETI@home account, we define how the individual clients or pods are utilized. The CPU utilization is left at the default value of 100% and after about 5 minutes you can see how the CPU utilization of all cluster nodes increases to 100% and remains constant at this value (see Figure 33). The cluster now computes data of the SETI@home project.
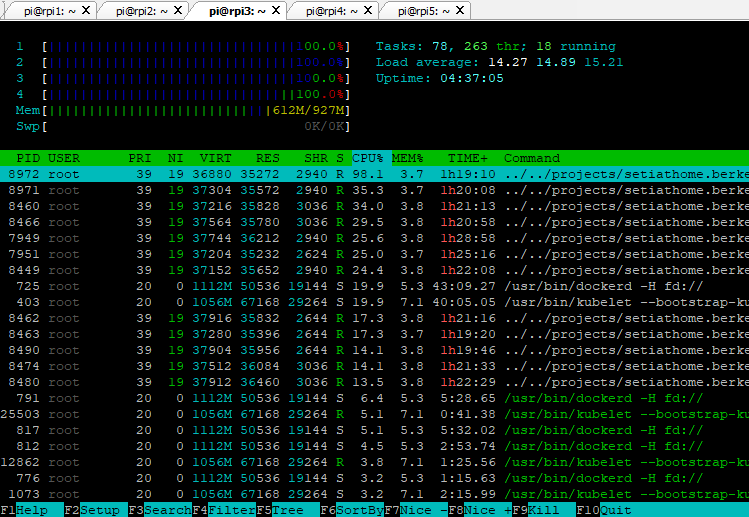
Figure 33: The CPU utilization of node rpi3 at 100%.
Figure 33 shows the computers currently logged in to the grid with our account information. Each pod is identified here as a single client. If we now assume that the number of PiCube clusters increases to ten, the number of pods would multiply by the same factor. With 10 pod instances per cluster, this means 100 active SETI@home clients, which could make their computing power available to the BOINC grid.
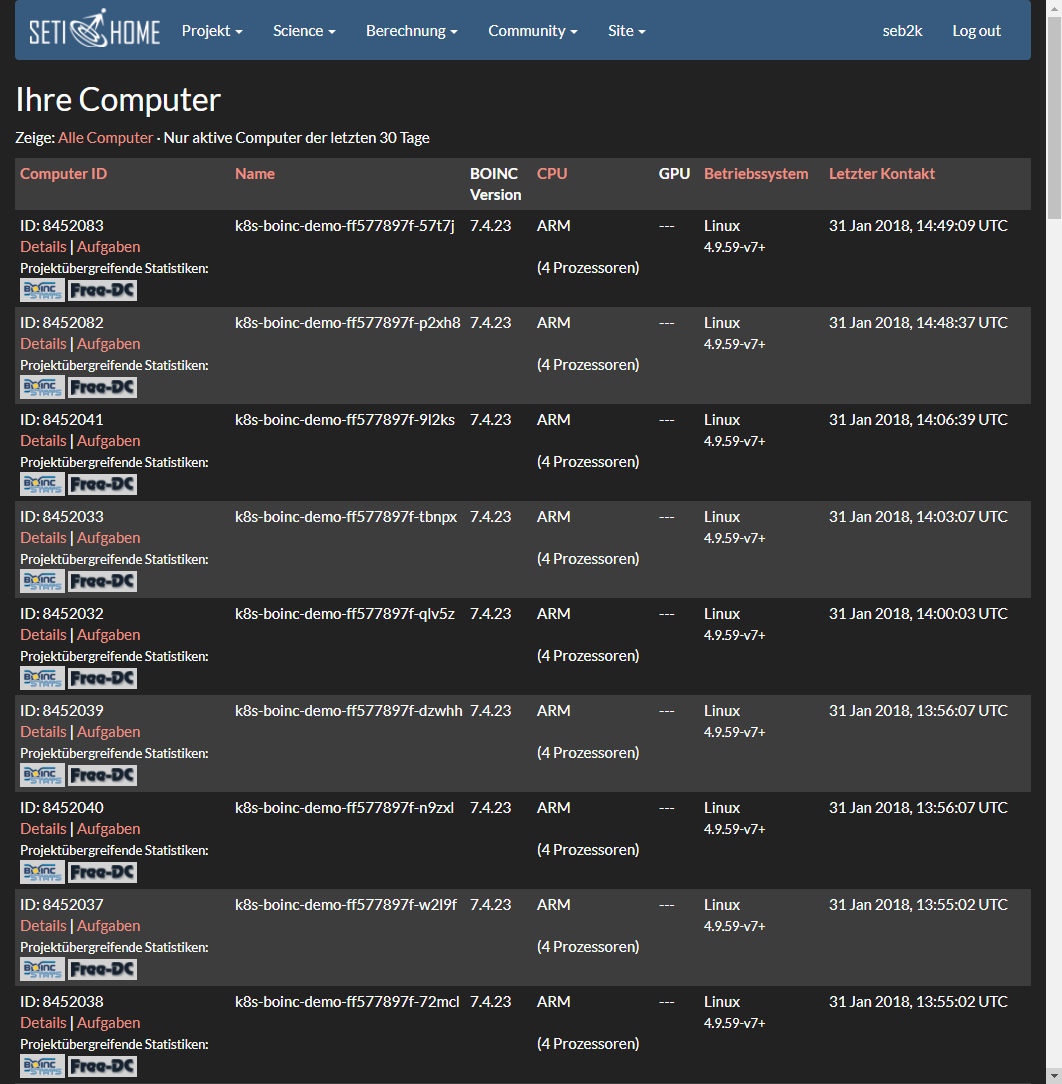
Figure 34: Listing of all logged-in clients or pods in our cluster.
As this use case shows, it can be inferred that the scientific utility of this cluster is without question. Using dynamic pod scaling, it is demonstrated that even when individual nodes have low performance, they can achieve high computing performance when combined as a swarm. BOINC's computing grid is a typical example of how computers, distributed around the world and connected via the Internet, can solve problems together.
Conclusion and outlook
It is possible to construct a comparable system of a supercomputer with low costs. It is obvious that the performance of an ARM processor cannot currently keep up with commercially available CISC processors, as described in Cost efficiency and performance. However, the use case and illustration of dynamic scaling show that once distributed systems are interconnected, they develop very high parallel computing power. The Raspberry Pi cluster provides an interesting approach to perform tests or use cases in research, education, and academia. ARM architectures are evolving rapidly in terms of performance and efficiency over the next few years, with power consumption always in mind. The requirements set at the beginning of this thesis, such as energy efficiency, resilience and modularity, have been met and sensibly implemented in the construct. There is no question that this PiCube cluster is not a real competitor to massively parallelized supercomputers, but the decisive approach lies in the benefit of a computing grid.
There are several ways to use this system in the future. On the one hand, its simplicity means it can be used for cluster computing to provide a small, full-featured, low-cost, energy-efficient development platform. This includes understanding its limitations in terms of performance, usability and maintainability. On the other hand, it can act as a mobile and self-sufficient cloud in a box system by adding components such as solar cells and mobile connectivity. Either way, it will remain a fascinating project that offers developers many possibilities and gives a think-out-of-the-box approach.
Check out the full project
- Conception, Construction and Evaluation of a Reaspberry Pi Cluster (1/4)
- Conception, Construction and Evaluation of a Reaspberry Pi Cluster (2/4)
Full project see Conception, Construction and Evaluation of a Reaspberry Pi Cluster
Bibliography
Adams, J. (September 2017). SFT Guide 14/17 - Raspberry Pi Tips, Tricks & Hacks (No. 1). Third generation: The innovations of the Raspberry Pi 3, p. 159.
Baier, J. (2017). Getting Started with Kubernetes - Harness the power of Kubernetes to manage Docker deployments with ease. Birmingham: Packt Publishing.
Bauke, H., & Mertens, S. (2006). Cluster computing - Practical introduction to high performance computing on Linux clusters. Heidelberg: Springer.
Bedner, M. (2012). Cloud computing - technology, security and legal design. Kassel: kassel university press.
Bengel, G., Baun, C., Kunze, M., & Stucky, K.-U. (2008). Master course parallel and distributed systems - fundamentals and programming of multicore processors, multiprocessors, clusters and grids. Wiesbaden: Vieweg+Teubner.
Beowulf Cluster Computing. (January 12, 2018). Retrieved from MichiganTech - Beowulf Cluster Computing: http://www.cs.mtu.edu/beowulf/
Beowulf Scalable Mass Storage (T-Racks). (January 12, 2018). Retrieved from ESS Project: https://www.hq.nasa.gov/hpcc/reports/annrpt97/accomps/ess/WW80.html
BOINC - Active Projects Statistics. (January 31, 2018). Retrieved from Free-DC - Distributed Computing Stats System: http://stats.free-dc.org/stats.php?page=userbycpid&cpid=cfbdd0ffc5596f8c5fed01bbe619679d
Cache.(January 14, 2018). Retrieved from Electronics Compendium: https://www.elektronik-kompendium.de/sites/com/0309291.htm
Christl, D.,Riedel, M., & Zelend, M. (2007). Communication systems / computer networks - Research of tools for the control of a massively parallel cluster computer in the computer center of the West Saxon University of Applied Sciences Zwickau. Zwickau: Westsächsichen Hochschule Zwickau.
CISC and RISC. (January 28, 2018). Retrieved from Electronics Compendium: https://www.elektronik-kompendium.de/sites/com/0412281.htm
Containersvs. virtual machines. (December 13, 2017). Retrieved from NetApp Blog: https://blog.netapp.com/blogs/containers-vs-vms/
Coulouris, G.,Dollimore, J., Kindberg, T., & Blair, G. (2012). Distributed systems - concepts and design. Boston: Pearson.
Dennis, A. K. (2013). Raspberry Pi super cluster. Birmingham: Packt Publishing.
The science behind SETI@home. (January 30, 2018). Retrieved from SETI@home: https://setiathome.berkeley.edu/sah_about.php
Docker on the Raspberry Pi with HypriotOS. (January 24, 2018). Retrieved from Raspberry Pi Geek: http://www.raspberry-pi-geek.de/Magazin/2017/12/Docker-auf-dem-Raspberry-Pi-mit-HypriotOS
Eder,M. (2016). Hypervisor- vs. container-based virtualization. Munich: Technical University of Munich.
Einstein@Home on Android devices. (January 23, 2018). Retrieved from GEO600: http://www.geo600.org/1282133/Einstein_Home_on_Android_devices
Enable I2C Interface on the Raspberry Pi. (January 28, 2018). Retrieved from Raspberry Pi Spy: https://www.raspberrypi-spy.co.uk/2014/11/enabling-the-i2c-interface-on-the-raspberry-pi/
Encyclopedia - VAX. (January 20, 2018). Retrieved from PCmag: https://www.pcmag.com/encyclopedia/term/53678/vax
Failover Cluster. (January 20, 2018). Retrieved from Microsoft Developer Network: https://msdn.microsoft.com/en-us/library/ff650328.aspx
Fenner, P. (10. 12 2017). So What's a Practical Laser-Cut Clip Size? Retrieved from DefProc Engineering: https://www.deferredprocrastination.co.uk/blog/2013/so-whats-a-practical-laser-cut-clip-size/Fey, D. (2010).
Grid computing - An enabling technology for computational science. Heidelberg: Springer.
GitHub - flash. (January 24, 2018). Retrieved from hypriot / flash: https://github.com/hypriot/flash
Goasguen, S. (2015). Docker Cookbook - Solutions and Examples for Building Dsitributed Applications. Sebastopol: O'Reilly.
Grabsch, V., & Radunz, Y. (2008). Seminar presentation - Amdahl's and Gustafson's law. o.O.: Creative Commons.
Herminghaus, V., & Scriba, A. (2006). Veritas Storage Foundation - High End Computing for UNIX Design and Implementation of High Availability Solutions with VxVM and VCS. Heidelberg: Springer.
Horizontal Pod Autoscaling. (January 29, 2018). Retrieved from GitHub: https://github.com/kubernetes/kubernetes/blob/8caeec429ee1d2a9df7b7a41b21c626346b456fb/docs/user-guide/horizontal-pod-autoscaling/image/index.php
How nodes work. (January 27, 2018). Retrieved from docker docs: https://docs.docker.com/engine/swarm/how-swarm-mode-works/nodes/
How to setup an I2C LCD on the Raspberry Pi. (January 28, 2018). Retrieved from Circuit Basics: http://www.circuitbasics.com/raspberry-pi-i2c-lcd-set-up-and-programming/
If we want to Find Aliens, We Need to Save the Arecibo Telescope. (January 23, 2018). Retrieved from vice: https://www.vice.com/en_us/article/wdbq74/find-aliens-arecibo-telescope
Inkscape - Overview. (January 24, 2018). Retrieved from Inkscape: https://inkscape.org/de/ueber/uebersicht/
Kaiser, R. (2009). Virtualization of multiprocessor systems with real-time applications. Koblenz-Landau.Kersken, S. (2015).
IT handbook for IT specialists. Bonn: Rheinwerk Verlag GmbH.
Kroeker, K. L. (March 2011). Grid computing's future. Communications of the ACM, pp. 15-17.
Kubernetes Components. (January 10, 2018). Retrieved from kubernetes: https://kubernetes.io/docs/concepts/overview/components/
Kubernetes vs Docker Swarm. (January 10, 2018). Retrieved from Platform9: https://platform9.com/blog/kubernetes-docker-swarm-compared/
Laser-Cut Elastic-Clipped Comb-Joints. (December 1, 2018). Retrieved from DefProc Engineering: https://www.deferredprocrastination.co.uk/blog/2013/laser-cut-elastic-clipped-comb-joints/
Laser-Cut Elastic Clips. (December 1, 2017). Retrieved from Thingiverse: https://www.thingiverse.com/thing:53032
Lee, C. (2014). Cloud database development and management. Boca Raton: CRC Press.
Liebel, O. (2011). Linux high availability - deployment scenarios and practical solutions. Bonn: Galileo Press.
Load-Balanced Cluster. (January 20, 2018). Retrieved from Microsoft Developer Network: https://msdn.microsoft.com/en-us/library/ff648960.aspx
Lobel, L. G., & Boyd, E. D.. (2014). Microsoft Azure SQL Database step by step. Redmond: Microsoft Press.
MAD - Andreas Gregori. (January 24, 2018). Retrieved from MAD Models Architecture Design: http://mad-modelle.de/kontakt/
Mandl, P. (2010). Basic course operating systems - architectures, resource management, synchronization, process communication. Wiesbaden: VIeweg + Teubner.
Matros, R. (2012). The impact of cloud computing on IT service providers - A case study-based investigation of critical influencing variables. Bayreuth: Springer
Gabler.Merkert, J. (16 October 2017). c't Raspberry Pi - Raspi projects. Risc OS, p. 151.
Miell, I., & Sayers, A. H. (2016). Docker in practice. New York: Manning Publications.
Networked computing: fundamentals and applications. (January 20, 2018). Retrieved from techchannel: https://www.tecchannel.de/a/networked-computing-grundlagen-und-anwendungen,439222,5
Neuenschwander, E. P. (2014). Cloud computing - A legal thundercloud? Zurich: University of Zurich.
New DIY supercomputer saves £1,000s. (January 8, 2018). Retrieved from University of Westminster: https://www.westminster.ac.uk/news-and-events/news/2011/new-diy-supercomputer-saves-%C2%A31000s
Nickoloff, J. (2016). Docker in action. New York: Manning Publications.
Nodes. (January 10, 2018). Retrieved from kubernetes: https://kubernetes.io/docs/concepts/workloads/pods/pod-overview/
Overview of Microsoft HPC Pack and SOA in Failover Cluster. (January 21, 2018). Retrieved from Microsoft TechNet: https://technet.microsoft.com/en-us/library/gg142067(v=ws.11).aspx
PaaS or IaaS. (January 13, 2018). Retrieved from Microsoft Azure: https://docs.microsoft.com/de-de/azure/sql-database/sql-database-paas-vs-sql-server-iaas
Parallel Linux Operating System - Beowulf Gigaflop/s Workstation Project. (January 12, 2018). Retrieved from ESS Project: https://www.hq.nasa.gov/hpcc/reports/annrpt97/accomps/ess/WW49.html
Pfister, G. (1997). In Search of Clusters - The ongoing Battle in lowly Parallel Computing. New Jersey: Prentice Hall.
Pods. (January 10, 2018). Retrieved from kubernetes: https://kubernetes.io/docs/concepts/workloads/pods/pod-overview/
Pods and Nodes. (January 10, 2018). Retrieved from kubernetes Bootcamp: https://kubernetesbootcamp.github.io/kubernetes-bootcamp/3-1.html
Project list. (January 8, 2018). Retrieved from BOINC: http://boinc.berkeley.edu/wiki/Project_list
Project to setup Boinc client in Docker for the RaspberryPi. (January 30, 2018). Retrieved from Docker Hub: https://hub.docker.com/r/bunchc/rpi-boinc/
projects. (November 30, 2017). Retrieved from Climbers.net: http://climbers.net/sbc/diy-raspberry-pi-3-cluster/RPiCluster4b.png
Raspberry Pi 3 - self-heating. (Dec 20, 2017). Retrieved from mikrocontroller.net: https://www.mikrocontroller.net/topic/393898
Raspberry Pi 3 GPIO Pin Chart with Pi. (January 23, 2018). Retrieved from openclipart: https://openclipart.org/detail/280972/raspberry-pi-3-gpio-pin-chart-with-pi
Raspberry Pi 3: Power consumption and CoreMark comparison. (January 31, 2018). Retrieved from heise online: https://www.heise.de/ct/artikel/Raspberry-Pi-3-Leistungsaufnahme-und-CoreMark-Vergleich-3121139.html
Ries, C. B. (2012). BOINC - high performance computing with Berkeley Open Infrastructure for Network Computing. Heidelberg: Springer Vieweg.
rkt - A security-minded, standards-based container engine. (January 27, 2018). Retrieved from CoreOS: https://coreos.com/rkt/
RPiCluster - Overview. (January 23, 2018). Retrieved from RPiCluster: https://bitbucket.org/jkiepert/rpicluster
Schill, A., & Springer, T. (2007). Distributed systems - fundamentals and enabling technologies. Heidelberg: Springer.
SETI@home - Your Computers. (January 31, 2018). Retrieved from SETI@home: https://setiathome.berkeley.edu/hosts_user.php
Smith, N. (28. 11 2017). Climbers.net. Retrieved from DIY 5 Node Cluster of Raspberry Pi 3s: http://climbers.net/sbc/diy-raspberry-pi-3-cluster/
Swarm mode key concepts. (January 27, 2018). Retrieved from docker docs: https://docs.docker.com/engine/swarm/key-concepts/
Tanenbaum, A. S. (2007). Distributed systems - principles and paradigms. New Jersey: Pearson Prentice Hall.
Technet. (January 13, 2018). Retrieved from Microsoft: https://blogs.technet.microsoft.com/kevinremde/2011/04/03/saas-paas-and-iaas-oh-my-cloudy-april-part-3/
Top500 List. (January 8, 2018). Retrieved from Top 500 The List: https://www.top500.org/list/2017/11/
Ulmann, B. (February 6, 2014). IT basics. FOM.
Our home galaxy - the Milky Way. (January 23, 2018). Retrieved from planet wissen: https://www.planet-wissen.de/technik/weltraumforschung/astronomie/pwieunsereheimatgalaxiediemilchstrasse100.html
VMS Software, Inc. Named Exclusive Developer of Future Versions of OpenVMS Operating System. (January 20, 2018). Retrieved from BusinessWire: https://www.businesswire.com/news/home/20140731006118/en/VMS-Software-Named-Exclusive-Developer-Future-Versions
What is Kubernetes? (January 10, 2018). Retrieved from kubernetes: https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/
Appendix A - Script: Installing Kubernetes

Appendix B - Script: LCD display

Appendix C - Script: Docker Autoscaling
Dockerfile:
|
|
index.php:
|
|
-
Cf. (Horizontal Pod Autoscaling, 2018). ↩︎
-
Cf. (Baier, 2017, p. 117). ↩︎
-
Cf. (Raspberry Pi 3: Power consumption and CoreMark comparison, 2018). . ↩︎
-
Cf. (The Science Behind SETI@home, 2018) ; Cf. (BOINC - Active Projects Statistics, 2018) ↩︎
-
Cf. (Project to setup Boinc client in Docker for the RaspberryPi, 2018). ↩︎